About
gradslam is an open-source framework providing differentiable building blocks for simultaneous localization and mapping (SLAM) systems. We enable the usage of dense SLAM subsystems from the comfort of PyTorch.
Code available at our GitHub repository
A longer technical report of our ICRA 2020 paper is available here

Abstract
The question of “representation” is central in the context of dense simultaneous localization and mapping (SLAM). Newer learning-based approaches have the potential to leverage data or task performance to directly inform the choice of representation. However, learning representations for SLAM has been an open question, because traditional SLAM systems are not end-to-end differentiable. In this work, we present gradSLAM, a differentiable computational graph take on SLAM. Leveraging the automatic differentiation capabilities of computational graphs, gradSLAM enables the design of SLAM systems that allow for gradient-based learning across each of their components, or the system as a whole. This is achieved by creating differentiable alternatives for each non-differentiable component in a typical dense SLAM system. Specifically, we demonstrate how to design differentiable trust-region optimizers, surface measurement and fusion schemes, as well as differentiate over rays, without sacrificing performance. This amalgamation of dense SLAM with computational graphs enables us to backprop all the way from 3D maps to 2D pixels, opening up new possibilities in gradient-based learning for SLAM.
Differentiable SLAM components
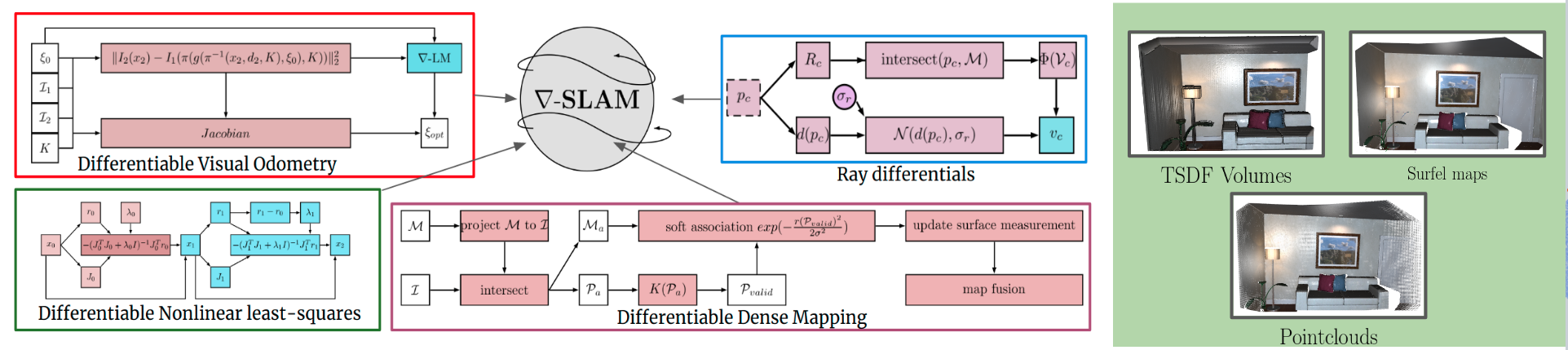
gradslam is a fully differentiable dense SLAM framework. It provides a repository of differentiable building blocks for a dense SLAM system, such as differentiable nonlinear least squares solvers, differentiable ICP (iterative closest point) techniques, differentiable raycasting modules, and differentiable mapping/fusion blocks. One can use these blocks to construct SLAM systems that allow gradients to flow all the way from the outputs of the system (map, trajectory) to the inputs (raw color/depth images, parameters, calibration, etc.).
Specifically, we implement differentiable versions three classical dense SLAM systems using the gradslam framework: KinectFusion, PointFusion, ICP-SLAM. We choose these because
- Each of these approaches sparked a new line-of-research in dense SLAM
- The approaches themselves are fairly simple from an algorithmic standpoint
- We aim to provide differentiable SLAM solutions for a wide variety of 3D representations (voxels, surfels, points).
Qualitative results
The differentiable SLAM systems perform quite similarly to the non-differentiable counterparts, while allowing for gradients to flow right through. This makes gradSLAM attractively poised to be used in gradient-based learning systems.
Here’s a comparative analysis of the three differentiable SLAM systems we provide.

More qualitative results, this time, on the ScanNet dataset.

Further, we have evaluated gradslam on the TUM RGB-D benchmark, as well as on an in-house sequence captured from an Intel RealSense D435 camera.


Paper

An earlier version of this paper has been presented at the international conference on robotics and automation (ICRA), 2020.
Citing us
If you would like to cite us, you could use the following BibTeX entry.
@article{gradslam,
author = { {Krishna Murthy}, Jatavallabhula and Saryazdi, Soroush and Iyer, Ganesh and Paull, Liam },
title = { gradSLAM: Dense SLAM meets Automatic Differentiation },
journal = { arXiv },
year = { 2020 },
}
Correspondence
If you need to discuss any further, or seek clarifications on implementation detail, correspondence is encouraged to Krishna Murthy, Soroush Saryazdi, Ganesh Iyer, or Liam Paull. Also, we would like to hear more from anyone working on similar ideas.
Acknowledgements
The authors are grateful to the wonderful help from several people, including, but not limited to, Gunshi Gupta, Ankur Handa, Bhairav Mehta, Mark Van der Merwe, Aaditya Saraiya, Parv Parkhiya, Akshit Gandhi, Shubham Garg, Tejas Khot, Gautham Swaminathan, Zeeshan Zia, Ronald Clark, and Sajad Saeedi.